Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and all things Software 3.0
Brought to you by, Alessio + swyx

The podcast by and for AI Engineers! In 2023, over 1 million visitors came to Latent Space to hear about news, papers and interviews in Software 3.0.
We cover Foundation Models changing every domain in Code Generation, Multimodality, AI Agents, GPU Infra and more, directly from the founders, builders, and thinkers involved in pushing the cutting edge. Striving to give you both the definitive take on the Current Thing down to the first introduction to the tech you'll be using in the next 3 months! We break news and exclusive interviews from OpenAI, tiny (George Hotz), Databricks/MosaicML (Jon Frankle), Modular (Chris Lattner), Answer...
...see more
The podcast by and for AI Engineers! In 2023, over 1 million visitors came to Latent Space to hear about news, papers and interviews in Software 3.0. We cover Foundation Models changing every domain in Code Generation, Multimodality, AI Agents, GPU Infra and more, directly from the founders, builders, and thinkers involved in pushing the cutting edge. Striving to give you both the definitive take on the Current Thing down to the first introduction to the tech you'll be using in the next 3 months! We break news and exclusive interviews from OpenAI, tiny (George Hotz), Databricks/MosaicML (Jon Frankle), Modular (Chris Lattner), Answer...
...see more
Subscribe and Listen Anywhere
Recent Episodes of Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and all things Software 3.0
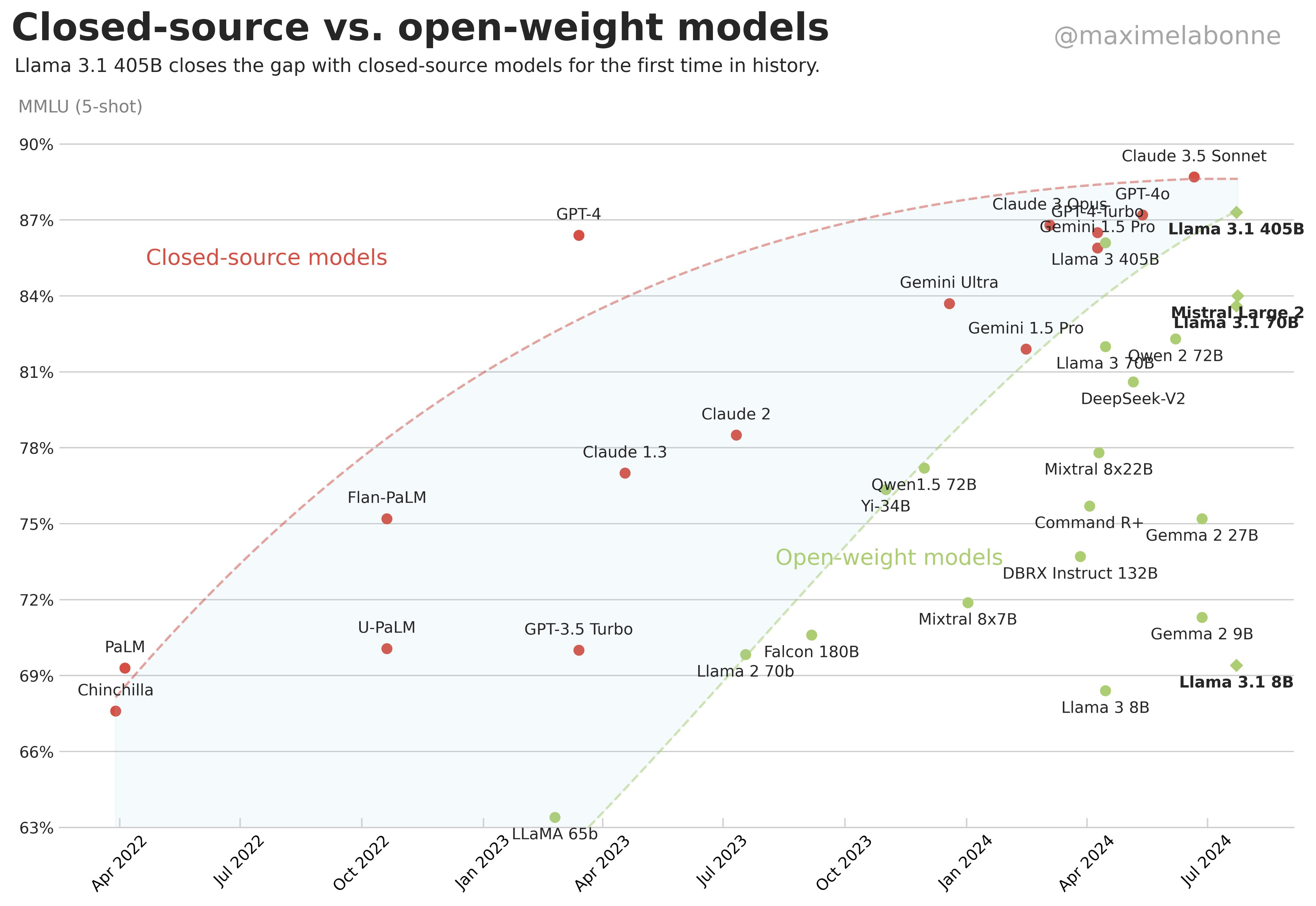
Efficiency is Coming: 3000x Faster, Cheaper, Better AI Inference from Hardware Improvements, Quantization, and Synthetic Data Distillation
AI Engineering is expanding! Join the first 🇬🇧 AI Engineer London meetup in Sept and get in touch for sponsoring the second 🗽 AI Engineer Summit in NYC this Dec!
The commoditization of intelligence takes on a few dimensions:
* Time to Open Model Equivalent: 15 months between GPT-4 and Llama 3.1 405B
* 10-100x CHEAPER/year: from $30/mtok for Claude 3 Opus to $3/mtok for L3-405B, and a 400x reduction in the frontier OpenAI model from 2022-2024. Notably, for personal use cases, both Gemini Flash and now Cerebras Inference offer 1m tokens/day inference free, causing the Open...
Episode • 3 September 2024 • 1h, 5m and 18s
Why you should write your own LLM benchmarks — with Nicholas Carlini, Google DeepMind
Today's guest, Nicholas Carlini, a research scientist at DeepMind, argues that we should be focusing more on what AI can do for us individually, rather than trying to have an answer for everyone.
"How I Use AI" - A Pragmatic Approach
Carlini's blog post "How I Use AI" went viral for good reason. Instead of giving a personal opinion about AI's potential, he simply laid out how he, as a security researcher, uses AI tools in his daily work. He divided it in 12 sections:
* To make applications
* As a tutor
<...Episode • 29 August 2024 • 1h, 10m and 5s

Is finetuning GPT4o worth it? — with Alistair Pullen, Cosine (Genie)
Betteridge's law says no: with seemingly infinite flavors of RAG, and >2million token context + prompt caching from Anthropic/Deepmind/Deepseek, it's reasonable to believe that "in context learning is all you need".
But then there’s Cosine Genie, the first to make a huge bet using OpenAI’s new GPT4o fine-tuning for code at the largest scale it has ever been used externally; resulting in what is now the #1 coding agent in the world according to SWE-Bench Full, Lite, and Verified:
SWE-Bench has been the most successful agent benchmark of the year, receiving honors at I...
Episode • 22 August 2024 • 1h, 5m and 19s
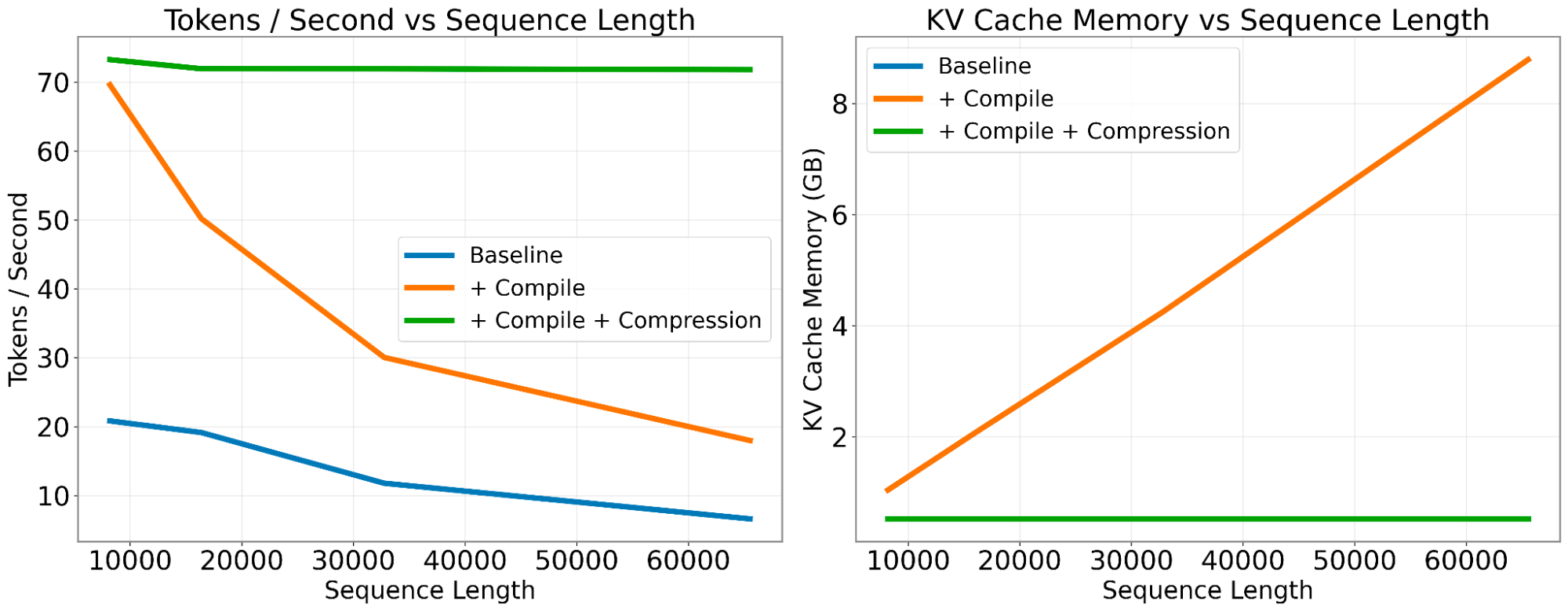
AI Magic: Shipping 1000s of successful products with no managers and a team of 12 — Jeremy Howard of Answer.ai
Disclaimer: We recorded this episode ~1.5 months ago, timing for the FastHTML release. It then got bottlenecked by Llama3.1, Winds of AI Winter, and SAM2 episodes, so we’re a little late. Since then FastHTML was released, swyx is building an app in it for AINews, and Anthropic has also released their prompt caching API.
Remember when Dylan Patel of SemiAnalysis coined the GPU Rich vs GPU Poor war? (if not, see our pod with him). The idea was that if you’re GPU poor you shouldn’t waste your time trying to solve GPU rich problems (i.e. pre...
Episode • 16 August 2024 • 58m and 56s

Segment Anything 2: Demo-first Model Development
Because of the nature of SAM, this is more video heavy than usual. See our YouTube!
Because vision is first among equals in multimodality, and yet SOTA vision language models are closed, we’ve always had an interest in learning what’s next in vision.
Our first viral episode was Segment Anything 1, and we have since covered LLaVA, IDEFICS, Adept, and Reka. But just like with Llama 3, FAIR holds a special place in our hearts as the New Kings of Open Source AI.
The list of sequels better than the originals is usually very...
Episode • 7 August 2024 • 1h, 3m and 30s

The Winds of AI Winter (Q2 Four Wars Recap) + ChatGPT Voice Mode Preview
Thank you for 1m downloads of the podcast and 2m readers of the Substack! 🎉
This is the audio discussion following The Winds of AI Winter essay that also serves as a recap of Q2 2024 in AI viewed through the lens of our Four Wars framework. Enjoy!
Full Video Discussion
Full show notes are here.
Timestamps
* [00:00:00] Intro Song by Suno.ai
* [00:02:01] Swyx and Alessio in Singapore
* [00:05:49] GPU Rich vs Poors: Frontier Labs
* [00:06:35] GPU Rich Frontier Models: Claude 3.5
* [00:10:37] GPU Ric...
Episode • 2 August 2024 • 1h, 55m and 1s
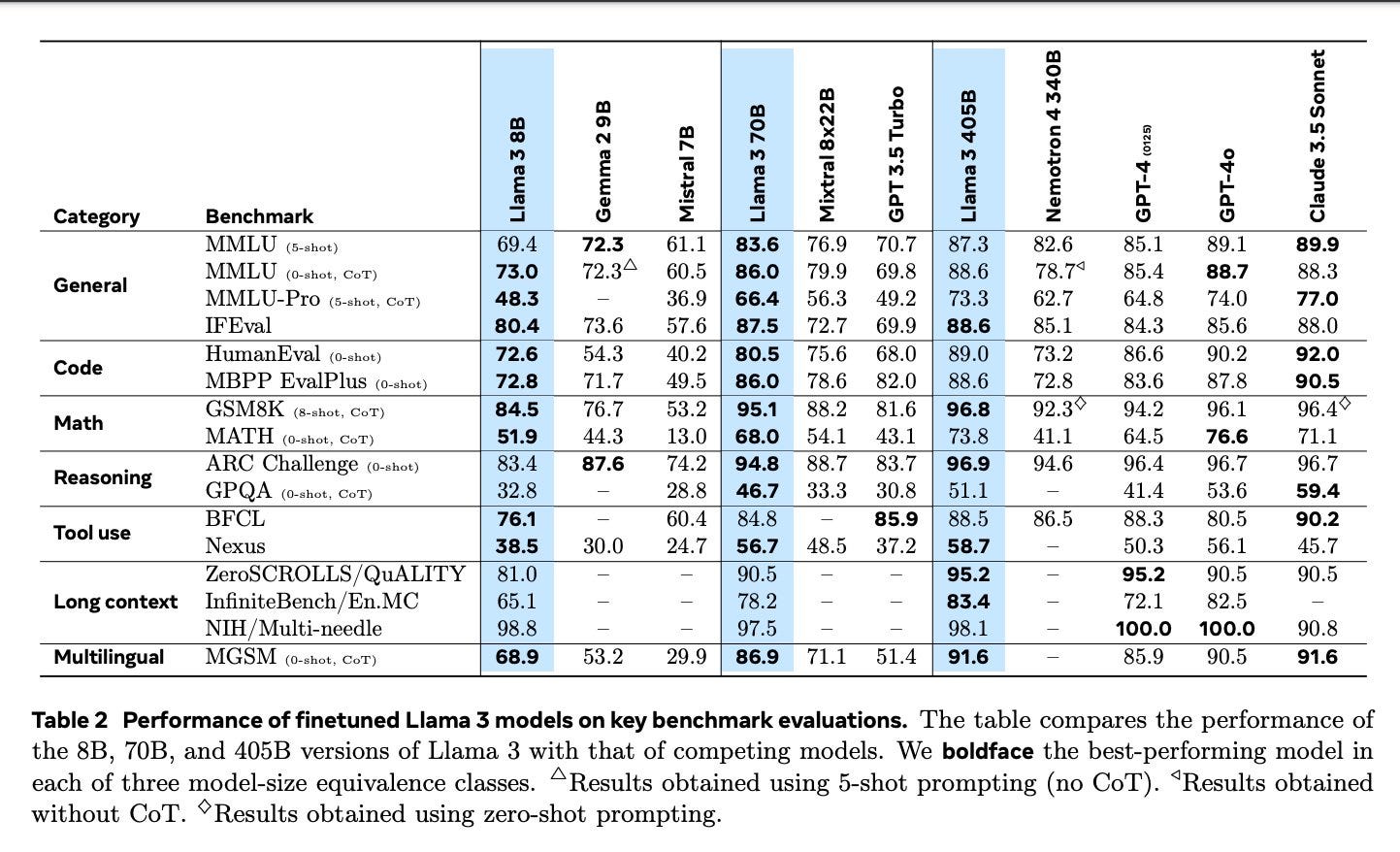
Llama 2, 3 & 4: Synthetic Data, RLHF, Agents on the path to Open Source AGI
If you see this in time, join our emergency LLM paper club on the Llama 3 paper!
For everyone else, join our special AI in Action club on the Latent Space Discord for a special feature with the Cursor cofounders on Composer, their newest coding agent!
Today, Meta is officially releasing the largest and most capable open model to date, Llama3-405B, a dense transformer trained on 15T tokens that beats GPT-4 on all major benchmarks:
The 8B and 70B models from the April Llama 3 release have also received serious spec bumps, warranting...
Episode • 23 July 2024 • 1h, 5m and 7s
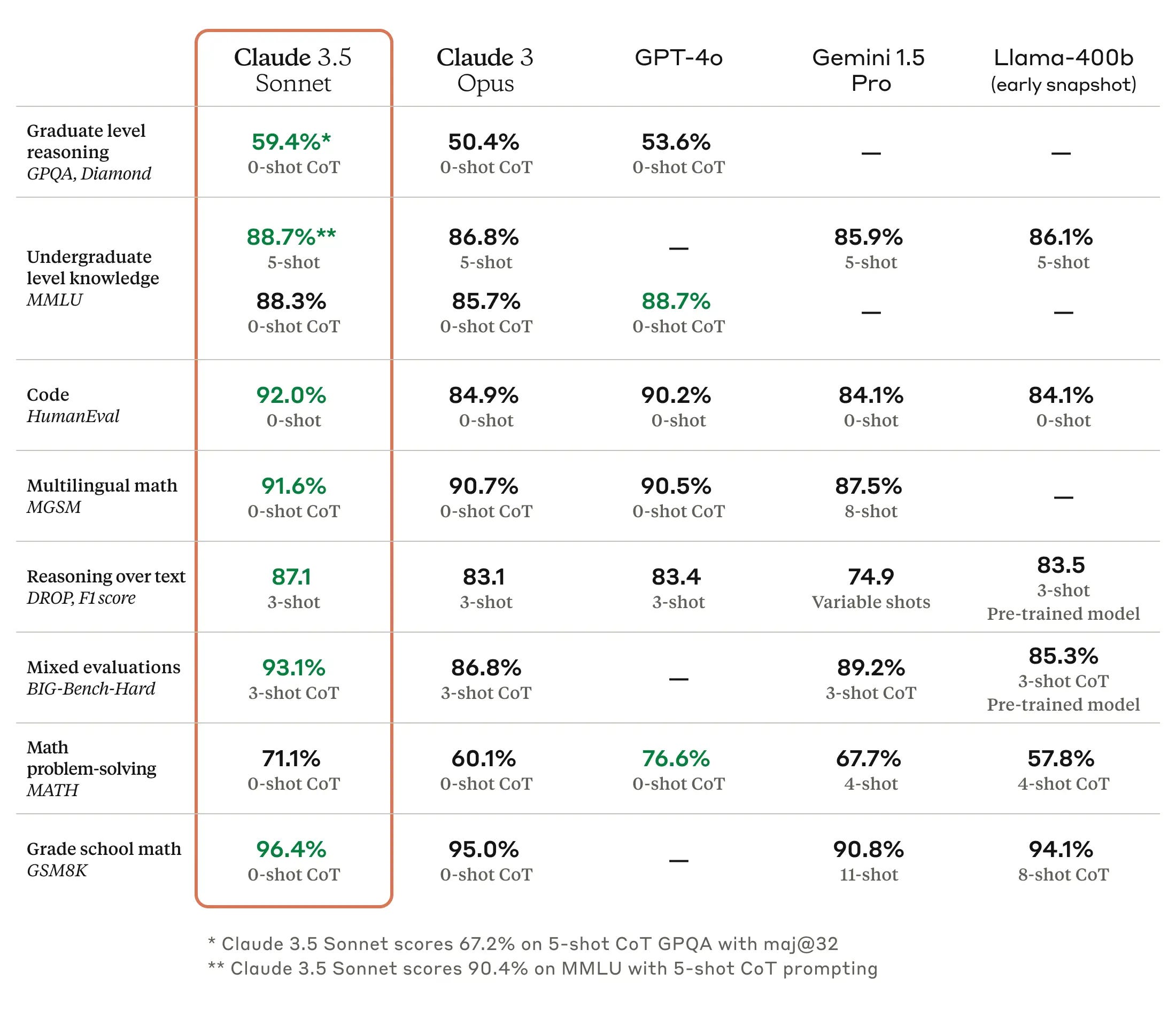
Benchmarks 201: Why Leaderboards > Arenas >> LLM-as-Judge
The first AI Engineer World’s Fair talks from OpenAI and Cognition are up!
In our Benchmarks 101 episode back in April 2023 we covered the history of AI benchmarks, their shortcomings, and our hopes for better ones.
Fast forward 1.5 years, the pace of model development has far exceeded the speed at which benchmarks are updated. Frontier labs are still using MMLU and HumanEval for model marketing, even though most models are reaching their natural plateau at a ~90% success rate (any higher and they’re probably just memorizing/overfitting).
From Benchmarks to Leaderboards
Outs...
Episode • 12 July 2024 • 58m and 29s

The 10,000x Yolo Researcher Metagame — with Yi Tay of Reka
Livestreams for the AI Engineer World’s Fair (Multimodality ft. the new GPT-4o demo, GPUs and Inference (ft. Cognition/Devin), CodeGen, Open Models tracks) are now live! Subscribe to @aidotEngineer to get notifications of the other workshops and tracks!
It’s easy to get de-sensitized to new models topping leaderboards every other week — however, the top of the LMsys leaderboard has typically been the exclusive domain of very large, very very well funded model labs like OpenAI, Anthropic, Google, and Meta. OpenAI had about 600 people at the time of GPT-4, and Google Gemini had 950 co-authors. This is why...
Episode • 5 July 2024 • 1h, 44m and 38s
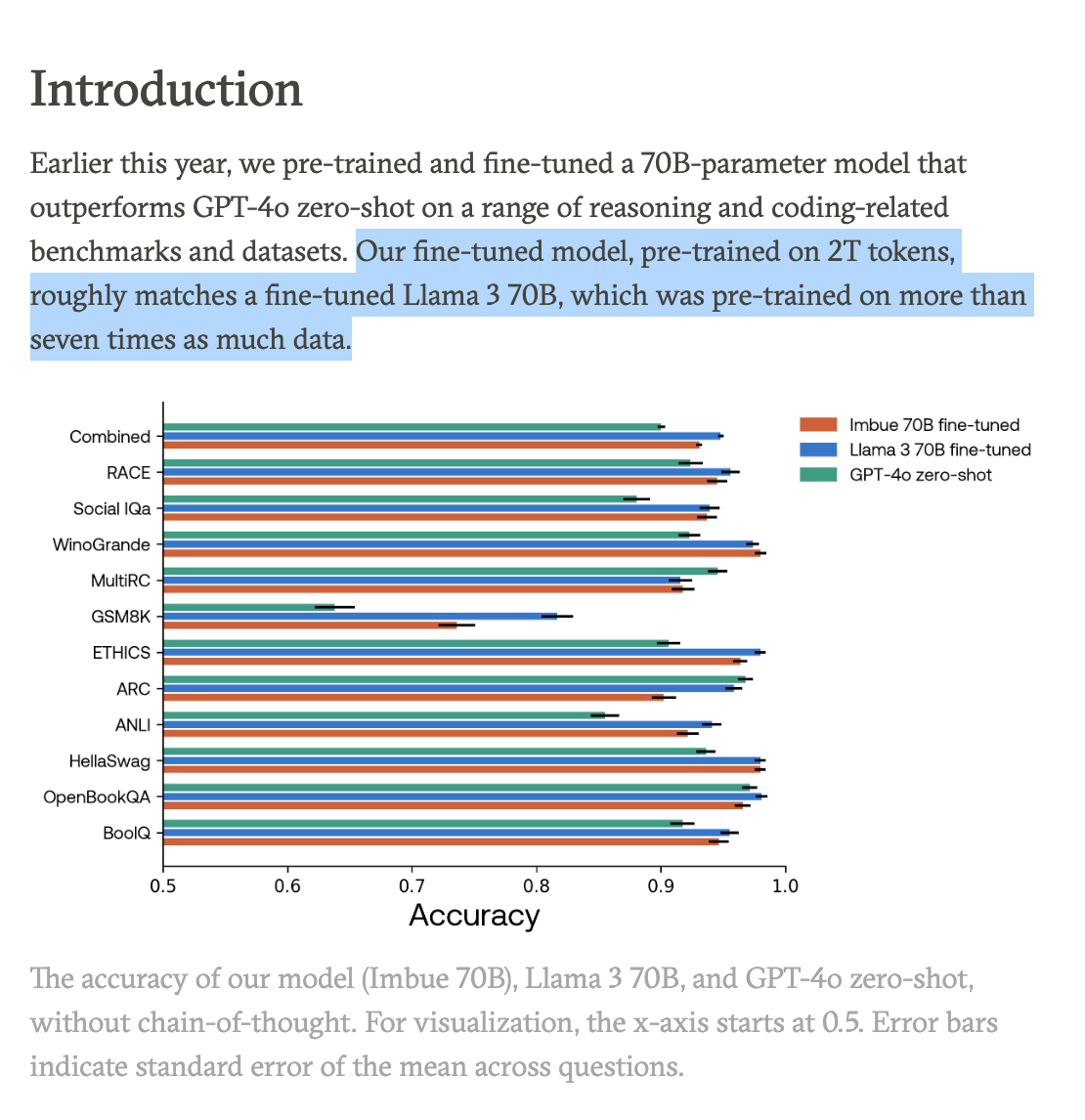
State of the Art: Training >70B LLMs on 10,000 H100 clusters
It’s return guest season here at Latent Space! We last talked to Kanjun in October and Jonathan in May (and December post Databricks acquisition):
Imbue and Databricks are back for a rare treat: a double-header interview talking about DBRX from Databricks and Imbue 70B, a new internal LLM that “outperforms GPT-4o” zero-shot on a range of reasoning and coding-related benchmarks and datasets, while using 7x less data than Llama 3 70B.
While Imbue, being an agents company rather than a model provider, are not releasing their models today, they a...
Episode • 25 June 2024 • 1h, 21m and 49s
© 2024 Skill Piper. All rights reserved